Spring
- 应用IOC和AOP机制,降低系统组件之间的耦合度,便于组件的维护扩展和替换。IOC特性可以降低action 和dao之间的关联,利用AOP进行事务管理或处理共通的部分程序已经做好了,其中一个需求发生改变,不需要大面积改变代码。spring相当于一个开发平台,在上面可以整合各种技术。
- IOC:控制反转,控制权的转移,应用程序本身不负责依赖对象的创建和维护,而是由外部容器负责创建和维护。获得依赖对象的过程被反转了。
- DI:依赖注入,IOC 的另一种表述。即组件以一些预定义好的方式(如 getter 方法)接受来自容器的注入。
- Bean生命周期
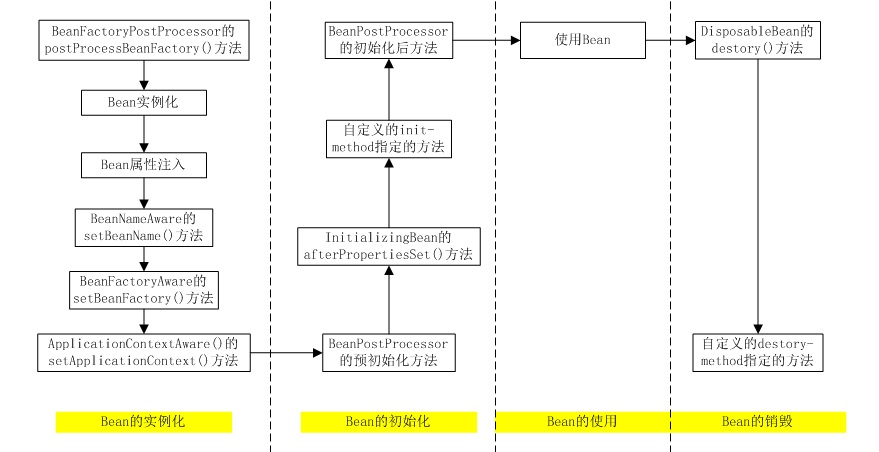
(1)BeanFactoryPostProcessor的postProcessorBeanFactory()方法:若某个IoC容器内添加了实现了BeanFactoryPostProcessor接口的实现类Bean,那么在该容器中实例化任何其他Bean之前可以回调该Bean中的postPrcessorBeanFactory()方法来对Bean的配置元数据进行更改,比如从XML配置文件中获取到的配置信息。
(2)Bean的实例化:Bean的实例化是使用反射实现的。
(3)Bean属性注入:Bean实例化完成后,利用反射技术实现属性及依赖Bean的注入。
(4)BeanNameAware的setBeanName()方法:如果某个Bean实现了BeanNameAware接口,那么Spring将会将Bean实例的ID传递给setBeanName()方法,在Bean类中新增一个beanName字段,并实现setBeanName()方法。
(5)BeanFactoryAware的setBeanFactory()方法:如果某个Bean实现了BeanFactoryAware接口,那么Spring将会将创建Bean的BeanFactory传递给setBeanFactory()方法,在Bean类中新增了一个beanFactory字段用来保存BeanFactory的值,并实现setBeanFactory()方法。
(6)ApplicationContextAware的setApplicationContext()方法:如果某个Bean实现了ApplicationContextAware接口,那么Spring将会将该Bean所在的上下文环境ApplicationContext传递给setApplicationContext()方法,在Bean类中新增一个ApplicationContext字段用来保存ApplicationContext的值,并实现setApplicationContext()方法。
(7)BeanPostProcessor预初始化方法:如果某个IoC容器中增加的实现BeanPostProcessor接口的实现类Bean,那么在该容器中实例化Bean之后,执行初始化之前会调用BeanPostProcessor中的postProcessBeforeInitialization()方法执行预初始化处理。
(8)InitializingBean的afterPropertiesSet()方法:如果Bean实现了InitializingBean接口,那么Bean在实例化完成后将会执行接口中的afterPropertiesSet()方法来进行初始化。
(9)自定义的inti-method指定的方法:如果配置文件中使用init-method属性指定了初始化方法,那么Bean在实例化完成后将会调用该属性指定的初始化方法进行Bean的初始化。
(10)BeanPostProcessor初始化后方法:如果某个IoC容器中增加的实现BeanPostProcessor接口的实现类Bean,那么在该容器中实例化Bean之后并且完成初始化调用后执行该接口中的postProcessorAfterInitialization()方法进行初始化后处理。
(11)使用Bean:此时有关Bean的所有准备工作均已完成,Bean可以被程序使用了,它们将会一直驻留在应用上下文中,直到该上下文环境被销毁。
(12)DisposableBean的destory()方法:如果Bean实现了DisposableBean接口,Spring将会在Bean实例销毁之前调用该接口的destory()方法,来完成一些销毁之前的处理工作。
(13)自定义的destory-method指定的方法:如果在配置文件中使用destory-method指定了销毁方法,那么在Bean实例销毁之前会调用该指定的方法完成一些销毁之前的处理工作。
1、BeanFactoryPostProcessor接口与BeanPostProcessor接口的作用范围是整个上下文环境中,使用方法是单独新增一个类来实现这些接口,那么在处理其他Bean的某些时刻就会回调响应的接口中的方法。
2、BeanNameAware、BeanFactoryAware、ApplicationContextAware的作用范围的Bean范围,即仅仅对实现了该接口的指定Bean有效,所有其使用方法是在要使用该功能的Bean自己来实现该接口。
3、第8点与第9点所述的两个初始化方法作用是一样的,我们完全可以使用其中的一种即可,一般情况我们使用第9点所述的方式,尽量少的去来Bean中实现某些接口,保持其独立性,低耦合性,尽量不要与Spring代码耦合在一起。第12和第13也是如此。applicationConfig.ml 中使用反射方式在 IOC 容器中创建 Bean。
AOP:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。主要功能是:日志记录,性能统计,安全控制,事务处理,异常处理等。
AOP实现方法:1.动态代理。2.AspectJ
使用@RequestMapping 注解映射请求的 URL。可以修饰类和方法。
@PathVariable 将占位符参数绑定到控制器处理方法的入参中。
@RequestParam 映射请求参数
@RequestHeader 映射请求头信息
POJO 作为处理方法的参数: Spring MVC 会按请求参数名和 POJO 属性名进行自动匹配,支持级联属性。
Session和Cookie的区别
- 在服务器端保存用户信息:在客户端保存用户信息
- Session中保存的是Object类型:在Cookie中保存的是String类型
- 随对话的结束而将其存储的数据销毁,重启浏览器Session 会失效,可以利用 Cookie 将 Session 持久化:Cookie可以长期保存在客户端
- 保存重要的信息:保存不重要的信息
ModelAndView
重定向:response.sendRedirect(),本质上相当于两次请求,地址栏的URL会变。
请求转发:request.getRequestDispatch().forward(req, resp),是一次请求,转发后请求对象会保存,地址栏URL不会变。
MyBatis正向工程:
- 导包
- Spring全局配置文件
- 写接口,接口不用实现(代理),与sql映射文件中的一句sql对应
- 写sql映射文件
- 获取使用
MyBatis逆向工程
- 导包
- Spring全局配置文件
- 建立数据库表
- 逆向工程配置文件
- 代码中运行该配置文件,生成接口和sql映射文件
- 获取使用
MyBatis缓存
- 一级缓存:SqlSession级别的缓存,一直开启。与数据库同一次会话期间查询到的数据会放在本地缓存中,以后可以直接从缓存取。两次相同查询期间执行了增删改操作,则缓存会失效。
- 二级缓存(全局缓存):基于namespace级别的缓存,一个namespace对应一个二级缓存。不同namespace(Mapper)对应的缓存放在自己的map中。只有关闭了会话后,数据才会从一级缓存存入二级缓存中。
EhCache是进程内的缓存框架,在集群模式下时,各应用服务器之间的缓存都是独立的,因此在不同服务器的进程间会存在缓存不一致的情况。即使EhCache提供了集群环境下的缓存同步策略,但是同步依然需要一定的时间,短暂的缓存不一致依然存在。在一些要求高一致性(任何数据变化都能及时的被查询到)的系统和应用中,需要使用集中式缓存,比如Redis。
JPA:JPA全称为Java Persistence API,JPA吸取了目前Java持久化技术的优点,旨在规范、简化Java对象的持久化工作。使用JPA持久化对象,并不是依赖于某一个ORM框架。
SpringData Repository
Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法.public interface Repository<T, ID extends Serializable> { }
Spring Data可以让我们只定义接口,只要遵循 Spring Data的规范,就无需写实现类。Repository是一个空接口,即一个标记接口,会被IOC容器识别为一个Repository Bean纳入到IOC容器中,进而可以在该接口中定义满足一定规范的方法。
基础的 Repository 提供了最基本的数据访问功能,其几个子接口则扩展了一些功能。它们的继承关系如下:
- Repository: 仅仅是一个标识,表明任何继承它的均为仓库接口类
- CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法
- PagingAndSortingRepository: 继承 CrudRepository,实现了一组分页排序相关的方法
- JpaRepository: 继承 PagingAndSortingRepository,实现一组 JPA 规范相关的方法
- 自定义的 XxxxRepository 需要继承 JpaRepository,这样的 XxxxRepository 接口就具备了通用的数据访问控制层的能力。
- JpaSpecificationExecutor: 不属于Repository体系,实现一组 JPA Criteria 查询相关的方法
ORM框架
Object Relational Mapping,对象-关系映射。项目中的业务实体有两种表现形式:对象和关系数据,即在内存中表现为对象,在数据库中表现为关系数据。
为什么需要ORM框架
因为对象之间可以存在关联和继承关系,但是在数据库中,关系数据无法表达多对多关联和继承关系。(ps:在数据库原理中,会把逻辑上的多对多转换为多个一对关系才能实现)因此,对象和关系(业务实体的两种表现形式)想要映射正确,项目系统一般以中间件的形式,即持久层框架。
Hibernate的特点
- Hibernate通过修改一个“持久化”对象的属性,从而修改数据库表中对应的记录数据
- 提供线程和进程两个级别的缓存提升应用程序性能
- 有丰富的映射方式将Java对象之间的关系(POJO)转换为数据库表之间的关系
- 屏蔽不同数据库实现之间的差异。在Hibernate中只需通过“方言”的形式指定当前使用的数据库,就可以根据底层数据库的实际情况生成适合的SQL语句
- 非侵入式。Hibernate不要求持久化类实现任何接口或继承任何类,POJO即可
Mybaits的特点:
- 简单易学。没有任何第三方依赖,最简单只需要2个jar包+几个sql映射文件,通过文档和源代码,即可比较完全的掌握它的设计思路和实现
- 灵活。不会对应用程序或者数据库的现有设计强加任何影响。Sql写在xml里面,便于统一管理和优化。通过sql基本上可以实现我们不使用数据访问框架可以实现的所有功能。
- 解除sql与程序代码的耦合。通过提供DAL层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。
- 提供映射标签,支持对象与数据库的ORM字段关系映射
- 提供对象关系映射标签,支持对象关系组建维护
- 提供xml标签,支持编写动态sql
比较
- Hibernate 对数据库提供了较为完整的封装,封装了基本的DAO层操作,有较好的数据库移植性
- Mybatis 可以进行更细致的SQL优化,查询必要的字段,但是需要维护SQL和查询结果集的映射,而且数据库的移植性较差,针对不同的数据库编写不同的SQL,
- Spring Data JPA 极大的简化了数据库访问,可以通过命名规范、注解的方式较快的编写SQL。