概述 注:本文基于Android 10源码,为了文章的简洁性,引用源码的地方可能有所删减。
官方注释: SurfaceFlinger accepts buffers, composes buffers, and sends buffers to the display.The most common consumer of image streams is SurfaceFlinger, the system service that consumes the currently visible surfaces and composites them onto the display using information provided by the Window Manager. SurfaceFlinger is the only service that can modify the content of the display. SurfaceFlinger uses OpenGL and the Hardware Composer to compose a group of surfaces.
SurfaceFlinger 用来管理消费当前可见的 Surface, 所有被渲染的可见 Surface 都会被 SurfaceFlinger 通过 WindowManager 提供的信息合成(使用 OpenGL 和 HardWare Composer)提交到屏幕的后缓冲区,等待屏幕的下一个 Vsync 信号到来,再显示到屏幕上。SufaceFlinger 通过屏幕后缓冲区与屏幕建立联系,同时通过 Surface 与上层建立联系,起到了一个承上启下的作用。
surfaceflinger 是在 Android 系统启动时解析 init.rc 文件(参考Android系统启动源码解析 )启动的守护进程,当 surfaceflinger 重启时会触发 zygote 重启。配置的 rc 文件位于 /system/etc/init/surfaceflinger.rc, 文件内容如下:
1 2 3 4 5 6 7 8 9 service surfaceflinger /system/bin/surfaceflinger class core animation user system group graphics drmrpc readproc onrestart restart zygote writepid /dev/stune/foreground/tasks socket pdx/system/vr/display/client stream 0666 system graphics u:object_r:pdx_display_client_endpoint_socket:s0 socket pdx/system/vr/display/manager stream 0666 system graphics u:object_r:pdx_display_manager_endpoint_socket:s0 socket pdx/system/vr/display/vsync stream 0666 system graphics u:object_r:pdx_display_vsync_endpoint_socket:s0
启动SurfaceFlinger 在解析执行了 init.rc 文件后,surfaceflinger 服务启动从 main_surfaceflinger.main() 方法开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int main (int , char **) ProcessState::self()->setThreadPoolMaxThreadCount(4 ); sp<ProcessState> ps (ProcessState::self()) ; ps->startThreadPool(); sp<SurfaceFlinger> flinger = new SurfaceFlinger(); setpriority(PRIO_PROCESS, 0 , PRIORITY_URGENT_DISPLAY); set_sched_policy(0 , SP_FOREGROUND); if (cpusets_enabled()) set_cpuset_policy(0 , SP_SYSTEM); flinger->init(); sp<IServiceManager> sm (defaultServiceManager()) ; sm->addService(String16(SurfaceFlinger::getServiceName()), flinger, false , IServiceManager::DUMP_FLAG_PRIORITY_CRITICAL); sp<GpuService> gpuservice = new GpuService(); sm->addService(String16(GpuService::SERVICE_NAME), gpuservice, false ); startDisplayService(); flinger->run(); return 0 ; }
从注释可以看出,该方法的主要功能如下:
设置 surfaceflinger 进程的 binder 线程池数最多为4,然后启动 binder 线程池;
创建 SurfaceFlinger 对象,将 surfaceflinger 进程设置为高优先级及使用前台调度策略;
初始化 SurfaceFlinger;
将 SurfaceFlinger 和 gpu Binder 服务注册到 ServiceManager;
启动 DisplayService;
在当前主线程执行 SurfaceFlinger.run 方法。
实例化SurfaceFlinger 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SurfaceFlinger::SurfaceFlinger() : SurfaceFlinger(SkipInitialization) { } void SurfaceFlinger::onFirstRef () mEventQueue->init(this ); } void MessageQueue::init (const sp<SurfaceFlinger>& flinger) mFlinger = flinger; mLooper = new Looper(true ); mHandler = new Handler(*this ); }
初始化SurfaceFlinger SF 初始化的逻辑在 SurfaceFlinger.init 方法里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void SurfaceFlinger::init () ALOGI("SurfaceFlinger's main thread ready to run. " "Initializing graphics H/W..." ); mEventThreadSource = std ::make_unique<DispSyncSource>(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs, true , "app" ); mEventThread = std ::make_unique<impl::EventThread>(mEventThreadSource.get(), [this ]() { resyncWithRateLimit(); }, impl::EventThread::InterceptVSyncsCallback(), "appEventThread" ); mSfEventThreadSource = std ::make_unique<DispSyncSource>(&mPrimaryDispSync, SurfaceFlinger::sfVsyncPhaseOffsetNs, true , "sf" ); mSFEventThread = std ::make_unique<impl::EventThread>(mSfEventThreadSource.get(), [this ]() { resyncWithRateLimit(); }, [this ](nsecs_t timestamp) { mInterceptor->saveVSyncEvent(timestamp); }, "sfEventThread" ); mEventQueue->setEventThread(mSFEventThread.get()); mVsyncModulator.setEventThread(mSFEventThread.get()); getBE().mRenderEngine = RE::impl::RenderEngine::create(HAL_PIXEL_FORMAT_RGBA_8888, hasWideColorDisplay ? RE::RenderEngine::WIDE_COLOR_SUPPORT : 0 ); getBE().mHwc.reset(new HWComposer(std ::make_unique<Hwc2::impl::Composer>(getBE().mHwcServiceName))); getBE().mHwc->registerCallback(this , getBE().mComposerSequenceId); processDisplayHotplugEventsLocked(); getDefaultDisplayDeviceLocked()->makeCurrent(); mEventControlThread = std ::make_unique<impl::EventControlThread>( [this ](bool enabled) { setVsyncEnabled(HWC_DISPLAY_PRIMARY, enabled); }); mDrawingState = mCurrentState; initializeDisplays(); if (mStartPropertySetThread->Start() != NO_ERROR) { ALOGE("Run StartPropertySetThread failed!" ); } }
SF 初始化时的主要功能:
创建 HWComposer 对象;
初始化非虚拟显示屏;
分别启动 app 和 sf 的 EventThread 线程,创建了两个 DispSyncSource 对象,分别是用于绘制(app)和合成(SurfaceFlinger);
启动开机动画服务;
向HWC注册回调 在前一节的 SurfaceFlinger.init 方法中有一行代码: getBE().mHwc->registerCallback(this, getBE().mComposerSequenceId) 给 HWComposer 注册了回调:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void HWComposer::registerCallback (HWC2::ComposerCallback* callback, int32_t sequenceId) mHwcDevice->registerCallback(callback, sequenceId); } void Device::registerCallback (ComposerCallback* callback, int32_t sequenceId) if (mRegisteredCallback) { ALOGW("Callback already registered. Ignored extra registration attempt." ); return ; } mRegisteredCallback = true ; sp<ComposerCallbackBridge> callbackBridge (new ComposerCallbackBridge(callback, sequenceId)) ; mComposer->registerCallback(callbackBridge); } void Composer::registerCallback (const sp<IComposerCallback>& callback) auto ret = mClient->registerCallback(callback); }
然后可以看一下 ComposerCallbackBridge 回调接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class ComposerCallbackBridge :public Hwc2::IComposerCallback { Return<void > onHotplug (Hwc2::Display display, IComposerCallback::Connection conn) override { HWC2::Connection connection = static_cast <HWC2::Connection>(conn); mCallback->onHotplugReceived(mSequenceId, display, connection); return Void(); } Return<void > onRefresh (Hwc2::Display display) override { mCallback->onRefreshReceived(mSequenceId, display); return Void(); } Return<void > onVsync (Hwc2::Display display, int64_t timestamp) override { mCallback->onVsyncReceived(mSequenceId, display, timestamp); return Void(); } };
上面 ComposerCallbackBridge 中的 mCallback 参数,传入的是 SurfaceFlinger 实例,它继承自 HWC2::ComposerCallback 接口,用来处理 HWC 的回调。
接收HWC回调 当 HWComposer 产生 Vsync 信号时,回调 ComposerCallbackBridge.onVsync 方法,进而调用 SF.onVsyncReceived 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void SurfaceFlinger::onVsyncReceived (int32_t sequenceId, hwc2_display_t displayId, int64_t timestamp) bool needsHwVsync = false ; { Mutex::Autolock _l(mHWVsyncLock); if (type == DisplayDevice::DISPLAY_PRIMARY && mPrimaryHWVsyncEnabled) { needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp); } } if (needsHwVsync) { enableHardwareVsync(); } else { disableHardwareVsync(false ); } }
mPrimaryDispSync 是一个 DispSync 对象,可以看出硬件产生的 Vsync 信号会交给同步模型 DispSync 的 addResyncSample 方法处理,根据该方法的返回值可以控制硬件是否继续发送垂直信号(SF.enableHardwareVsync & SF.disableHardwareVsync),即硬件的垂直信号并不是持续产生的,而是 DispSync 同步模型在需要(addResyncSample)的时候才 enable 的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void SurfaceFlinger::enableHardwareVsync () if (!mPrimaryHWVsyncEnabled && mHWVsyncAvailable) { mPrimaryDispSync.beginResync(); mEventControlThread->setVsyncEnabled(true ); mPrimaryHWVsyncEnabled = true ; } } void SurfaceFlinger::disableHardwareVsync (bool makeUnavailable) Mutex::Autolock _l(mHWVsyncLock); if (mPrimaryHWVsyncEnabled) { mEventControlThread->setVsyncEnabled(false ); mPrimaryDispSync.endResync(); mPrimaryHWVsyncEnabled = false ; } if (makeUnavailable) { mHWVsyncAvailable = false ; } }
可以看到是通过 EventControlThread 来完成的。
EventControlThread EventControlThread 线程用来控制 HWC 是否应该发送 Vsync 信号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 EventControlThread::EventControlThread(EventControlThread::SetVSyncEnabledFunction function) : mSetVSyncEnabled(function) { pthread_setname_np(mThread.native_handle(), "EventControlThread" ); } void EventControlThread::setVsyncEnabled (bool enabled) std ::lock_guard<std ::mutex> lock (mMutex) mVsyncEnabled = enabled; mCondition.notify_all(); } void EventControlThread::threadMain () NO_THREAD_SAFETY_ANALYSIS auto keepRunning = true ; auto currentVsyncEnabled = false ; while (keepRunning) { mSetVSyncEnabled(currentVsyncEnabled); std ::unique_lock<std ::mutex> lock (mMutex) mCondition.wait(lock, [this , currentVsyncEnabled, keepRunning]() NO_THREAD_SAFETY_ANALYSIS { return currentVsyncEnabled != mVsyncEnabled || keepRunning != mKeepRunning; }); currentVsyncEnabled = mVsyncEnabled; keepRunning = mKeepRunning; } } void SurfaceFlinger::setVsyncEnabled (int disp, int enabled) getHwComposer().setVsyncEnabled(disp, enabled ? HWC2::Vsync::Enable : HWC2::Vsync::Disable); }
可以看到默认会关闭 HWC Vsync 的发送,然后在执行 initializeDisplays 时会将其打开,调用流程: SF.initializeDisplays -> SF.onInitializeDisplays -> SF.setPowerModeInternal -> SF.resyncToHardwareVsync(true)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void SurfaceFlinger::resyncToHardwareVsync (bool makeAvailable) Mutex::Autolock _l(mHWVsyncLock); if (makeAvailable) { mHWVsyncAvailable = true ; } else if (!mHWVsyncAvailable) { return ; } const auto & activeConfig = getBE().mHwc->getActiveConfig(HWC_DISPLAY_PRIMARY); const nsecs_t period = activeConfig->getVsyncPeriod(); mPrimaryDispSync.reset(); mPrimaryDispSync.setPeriod(period); if (!mPrimaryHWVsyncEnabled) { mPrimaryDispSync.beginResync(); mEventControlThread->setVsyncEnabled(true ); mPrimaryHWVsyncEnabled = true ; } }
DispSync同步模型 在 SF 的初始化过程中创建了两个 DispSyncSource 对象,分别是 App 绘制延时源和 SF 合成延时源,这两个源都基于 mPrimaryDispSync—一个 DispSync 对象,是对硬件 Hwc 垂直信号的同步模型,它在 SF 的构造方法中实例化。这是 Android 的优化策略,因为在 Vsync 信号到来后如果同时进行 App 的绘制和 SF 的合成流程,则可能会竞争 CPU 资源,从而影响效率。因此引入了 Vsync 同步模型 DispSync, 该模型会根据需要打开硬件的 Vsync 信号进行采样,然后同步 DispSync 模型,从而为上层的 APP 绘制延时源和 SF 合成延时源提供 Vsync 信号,这两个延时源分别添加一个相位偏移量(即上面代码中的 vsyncPhaseOffsetNs 和 sfVsyncPhaseOffsetNs),以此错开在 Vsync 信号到来后 APP 绘制和 SF 合成的执行。
看一下 DispSync 的初始化:
1 DispSync::DispSync(const char * name) : mName(name), mRefreshSkipCount(0 ), mThread(new DispSyncThread(name)) {}
在 SurfaceFlinger 的构造函数里,会调用 mPrimaryDispSync.init 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void DispSync::init (bool hasSyncFramework, int64_t dispSyncPresentTimeOffset) mThread->run("DispSync" , PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE); reset(); beginResync(); } class DispSyncThread :public Thread { virtual bool threadLoop () while (true ) { } return false ; } }
在执行 DispSync 的初始化方法时会启动名为 DispSync 的线程, DispSync 线程通过调用 mCond.wait(mMutex) 阻塞自身线程,等待被唤醒。在接收到硬件 Vsync 信号后会回调到 SF.onVsyncReceived 方法,其中调用的 DispSync.addResyncSample 方法会更新同步模型的偏移量来使其和硬件的 VSYNC 信号同步,然后再通过 mCond.signal 唤醒 DispSync 线程。具体的算法就不看了,直接看 DispSync 线程被唤醒后的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 virtual bool threadLoop () while (true ) { targetTime = computeNextEventTimeLocked(now); if (now < targetTime) { } Vector<CallbackInvocation> callbackInvocations = gatherCallbackInvocationsLocked(now); if (callbackInvocations.size() > 0 ) { fireCallbackInvocations(callbackInvocations); } } return false ; } Vector<CallbackInvocation> gatherCallbackInvocationsLocked (nsecs_t now) { Vector<CallbackInvocation> callbackInvocations; nsecs_t onePeriodAgo = now - mPeriod; for (size_t i = 0 ; i < mEventListeners.size(); i++) { nsecs_t t = computeListenerNextEventTimeLocked(mEventListeners[i], onePeriodAgo); if (t < now) { CallbackInvocation ci; ci.mCallback = mEventListeners[i].mCallback; ci.mEventTime = t; callbackInvocations.push(ci); mEventListeners.editItemAt(i).mLastEventTime = t; } } return callbackInvocations; } void fireCallbackInvocations (const Vector<CallbackInvocation>& callbacks) for (size_t i = 0 ; i < callbacks.size(); i++) { callbacks[i].mCallback->onDispSyncEvent(callbacks[i].mEventTime); } } status_t DispSync::addEventListener (const char * name, nsecs_t phase, Callback* callback) return mThread->addEventListener(name, phase, callback); }
上面 DispSync.addEventListener 方法会添加 DispSync 同步模型的 Vsync 信号的监听器。
DispSyncSource延时源 上面已经讲过在 SF 的初始化过程中创建了两个 DispSyncSource 对象,分别是 App 绘制延时源和 SF 合成延时源,这两个源都基于 DispSync 同步模型来处理硬件 Vsync 信号,延时源通过对应的 EventThread 来管理。下面根据 DispSyncSource 源码看看从 DispSync 同步模型传递给 DispSyncSource 延时源的 Vsync 信号是怎么传递给需要的监听者的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class VSyncSource { class Callback { virtual void onVSyncEvent (nsecs_t when) 0 ; }; virtual void setVSyncEnabled (bool enable) 0 ; virtual void setCallback (Callback* callback) 0 ; virtual void setPhaseOffset (nsecs_t phaseOffset) 0 ; }; class DispSync { class Callback { virtual void onDispSyncEvent (nsecs_t when) 0 ; }; } class DispSyncSource final :public VSyncSource, private DispSync::Callback { DispSyncSource(DispSync* dispSync, nsecs_t phaseOffset, bool traceVsync, const char * name) : mName(name), mDispSync(dispSync), mPhaseOffset(phaseOffset), mEnabled(false ) {} void setVSyncEnabled (bool enable) override if (enable) { mDispSync->addEventListener(mName, mPhaseOffset, static_cast <DispSync::Callback*>(this )); } else { mDispSync->removeEventListener(static_cast <DispSync::Callback*>(this )); } mEnabled = enable; } void setCallback (VSyncSource::Callback* callback) override mCallback = callback; } virtual void onDispSyncEvent (nsecs_t when) VSyncSource::Callback* callback; { Mutex::Autolock lock (mCallbackMutex) ; callback = mCallback; } if (callback != nullptr ) { callback->onVSyncEvent(when); } } }
DispSyncSource 延时源通过 DispSync 同步模型来构造实例,DispSync 通过调用接口方法 onDispSyncEvent 来通知 DispSyncSource 延时源收到了 Vsync 信号,然后通过 DispSyncSource 延时源设置的 callback.onVSyncEvent 方法将 Vsync 信号的到达事件通知给监听者(其实就是EventThread)。
setVSyncEnabled: 控制是否监听来自于 DispSync 同步模型的 Vsync 信号
setCallback: 设置 DispSyncSource 延时源收到来自 DispSync 同步模型的 Vsync 信号后的监听者
onDispSyncEvent: DispSync 同步模型收到 Vsync 信号后通知 DispSyncSource 的回调方法,方法内部会回调通知通过 setCallback 方法设置的监听者(EventThread)
EventThread EventThread 用来负责管理 DispSyncSource 延时源,由于分别创建了用于 APP 绘制和 SF 合成的 DispSyncSource 源,因此也对应创建了两个分别用于管理它们的 EventThread 线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 EventThread::EventThread(VSyncSource* src, ResyncWithRateLimitCallback resyncWithRateLimitCallback, InterceptVSyncsCallback interceptVSyncsCallback, const char * threadName) : mVSyncSource(src), mResyncWithRateLimitCallback(resyncWithRateLimitCallback), mInterceptVSyncsCallback(interceptVSyncsCallback) { mThread = std ::thread(&EventThread::threadMain, this ); } void EventThread::threadMain () NO_THREAD_SAFETY_ANALYSIS while (mKeepRunning) { signalConnections = waitForEventLocked(&lock, &event); } }
ET.waitForEventLocked 启动了 EventThread 后,调用 threadMain 方法,我们看一下 waitForEventLocked 方法的注释: This will return when (1) a vsync event has been received, and (2) there was at least one connection interested in receiving it when we started waiting. 即 waitForEventLocked 方法只有当接收到了 Vsync 信号 且至少有一个 Connection 正在等待 Vsync 信号 才会返回,否则会调用 mCondition.wait/wait_for 方法一直等待:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 Vector<sp<EventThread::Connection> > EventThread::waitForEventLocked ( std ::unique_lock<std ::mutex>* lock, DisplayEventReceiver::Event* event) Vector<sp<EventThread::Connection> > signalConnections; while (signalConnections.isEmpty() && mKeepRunning) { bool eventPending = false ; bool waitForVSync = false ; size_t vsyncCount = 0 ; nsecs_t timestamp = 0 ; for (int32_t i = 0 ; i < DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES; i++) { timestamp = mVSyncEvent[i].header.timestamp; if (timestamp) { if (mInterceptVSyncsCallback) { mInterceptVSyncsCallback(timestamp); } *event = mVSyncEvent[i]; mVSyncEvent[i].header.timestamp = 0 ; vsyncCount = mVSyncEvent[i].vsync.count; break ; } } size_t count = mDisplayEventConnections.size(); for (size_t i = 0 ; i < count;) { sp<Connection> connection (mDisplayEventConnections[i].promote()) ; if (connection != nullptr ) { bool added = false ; if (connection->count >= 0 ) { waitForVSync = true ; if (timestamp) { if (connection->count == 0 ) { connection->count = -1 ; signalConnections.add(connection); added = true ; } else if (connection->count == 1 || (vsyncCount % connection->count) == 0 ) { signalConnections.add(connection); added = true ; } } } if (eventPending && !timestamp && !added) { signalConnections.add(connection); } ++i; } else { mDisplayEventConnections.removeAt(i); --count; } } if (timestamp && !waitForVSync) { disableVSyncLocked(); } else if (!timestamp && waitForVSync) { enableVSyncLocked(); } if (!timestamp && !eventPending) { if (waitForVSync) { bool softwareSync = mUseSoftwareVSync; auto timeout = softwareSync ? 16 ms : 1000 ms; if (mCondition.wait_for(*lock, timeout) == std ::cv_status::timeout) { } } else { mCondition.wait(*lock); } } } return signalConnections; }
看一下 disableVSyncLocked 和 enableVSyncLocked 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void EventThread::enableVSyncLocked () if (!mUseSoftwareVSync) { if (!mVsyncEnabled) { mVsyncEnabled = true ; mVSyncSource->setCallback(this ); mVSyncSource->setVSyncEnabled(true ); } } } void EventThread::disableVSyncLocked () if (mVsyncEnabled) { mVsyncEnabled = false ; mVSyncSource->setVSyncEnabled(false ); } }
可以看出 enableVSyncLocked 和 disableVSyncLocked 这两个方法的作用:通过 DispSyncSource 同步源向 DispSync 同步模型的 DispSyncThread 线程添加或移除对 DispSync 同步模型中 Vsync 信号的监听器。同时 enableVSyncLocked 方法还通过 DispSyncSource.setCallback 方法设置了在 DispSyncSource 延时源收到来自 DispSync 同步模型的 Vsync 信号后的监听者 。
Vsync 事件到达后会将其保存在参数 mVSyncEvent 中,如果 timestamp 为 0 则表示没有 Vsync 信号到达。在 mDisplayEventConnections 中保存了注册的监听者,如果 connection->count >= 0 则表示有监听者对 Vsync 信号感兴趣,于是 将 waitForVSync 置为 true 且将该监听者添加到 signalConnections 集合中。根据源码注释可知 connection.count 的含义如下:
count >= 1: continuous event. count is the vsync rate – 会持续接收 Vsync 事件
count == 0: one-shot event that has not fired – 只接受一次 Vsync 事件,初始化时 count 为 0
count == -1: one-shot event that fired this round / disabled – 不再接收 Vsync 事件
在取得了 timestamp 和 waitForVSync 的值后:
若 Vsync 信号已经到达但没有感兴趣的监听者 则 通过 disableVSyncLocked 方法移除 DispSyncSource 对 DispSync 同步模型的 Vsync 信号的监听 若有感兴趣的监听者但 Vsync 信号还未达到 则 通过 enableVSyncLocked 方法将 DispSyncSource 添加到 DispSync 同步模型的监听者集合 若 Vsync 信号未到达且没有其他等待的事件 则 如果 waitForVSync == true 则要等待 Vsync 信号(不会无限等待,有超时时间),否则阻塞当前线程
MQ.setEventThread 接下来 SF 初始化过程中调用了 MessageQueue.setEventThread 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void MessageQueue::setEventThread (android::EventThread* eventThread) if (mEventThread == eventThread) { return ; } if (mEventTube.getFd() >= 0 ) { mLooper->removeFd(mEventTube.getFd()); } mEventThread = eventThread; mEvents = eventThread->createEventConnection(); mEvents->stealReceiveChannel(&mEventTube); mLooper->addFd(mEventTube.getFd(), 0 , Looper::EVENT_INPUT, MessageQueue::cb_eventReceiver, this ); } sp<BnDisplayEventConnection> EventThread::createEventConnection () const { return new Connection(const_cast <EventThread*>(this )); } status_t EventThread::Connection::stealReceiveChannel(gui::BitTube* outChannel) { outChannel->setReceiveFd(mChannel.moveReceiveFd()); return NO_ERROR; } void EventThread::Connection::onFirstRef() { mEventThread->registerDisplayEventConnection(this ); } status_t EventThread::registerDisplayEventConnection ( const sp<EventThread::Connection>& connection) std ::lock_guard<std ::mutex> lock (mMutex) mDisplayEventConnections.add(connection); mCondition.notify_all(); return NO_ERROR; }
可以看到 MQ.setEventThread 方法创建了一个 Connection 连接且将其加入了 mDisplayEventConnections 列表 。接着调用 Looper.addFd 方法监听 mEventTube 中的数据,下面看下这个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int Looper::addFd (int fd, int ident, int events, Looper_callbackFunc callback, void * data) return addFd(fd, ident, events, callback ? new SimpleLooperCallback(callback) : NULL , data); } int Looper::addFd (int fd, int ident, int events, const sp<LooperCallback>& callback, void * data) if (!callback.get()) { if (!mAllowNonCallbacks) { ALOGE("Invalid attempt to set NULL callback but not allowed for this looper." ); return -1 ; } if (ident < 0 ) { ALOGE("Invalid attempt to set NULL callback with ident < 0." ); return -1 ; } } else { ident = POLL_CALLBACK; } Request request; request.fd = fd; request.ident = ident; request.events = events; request.callback = callback; request.data = data; ssize_t requestIndex = mRequests.indexOfKey(fd); if (requestIndex < 0 ) { mRequests.add(fd, request); } else { mRequests.replaceValueAt(requestIndex, request); } } SimpleLooperCallback::SimpleLooperCallback(Looper_callbackFunc callback) : mCallback(callback) { } int SimpleLooperCallback::handleEvent (int fd, int events, void * data) return mCallback(fd, events, data); }
调用 Looper.addFd 方法会根据传入的参数创建一个 request 对象,并将其加入 mRequests 列表。接下来会在 poll 方法中取出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 inline int pollOnce (int timeoutMillis) return pollOnce(timeoutMillis, NULL , NULL , NULL ); } int Looper::pollOnce (int timeoutMillis, int * outFd, int * outEvents, void ** outData) int result = 0 ; for (;;) { while (mResponseIndex < mResponses.size()) { const Response& response = mResponses.itemAt(mResponseIndex++); int ident = response.request.ident; if (ident >= 0 ) { return ident; } } if (result != 0 ) { return result; } result = pollInner(timeoutMillis); } } int Looper::pollInner (int timeoutMillis) for (size_t i = 0 ; i < mResponses.size(); i++) { Response& response = mResponses.editItemAt(i); if (response.request.ident == POLL_CALLBACK) { int fd = response.request.fd; int events = response.events; void * data = response.request.data; int callbackResult = response.request.callback->handleEvent(fd, events, data); if (callbackResult == 0 ) { removeFd(fd, response.request.seq); } result = POLL_CALLBACK; } } return result; }
因此,当调用 addFd 函数时传入的 fd 有数据接收时,则会根据传入的 callback 参数执行不同的逻辑:
callback 是一个函数时则 response.request.callback->handleEvent 直接调用该函数
callback 是一个对象时则 response.request.callback->handleEvent 调用的是该对象自定义的 handleEvent 方法
SurfaceFlinger.run 在 SurfaceFlinger 初始化完成后会调用其 run 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void SurfaceFlinger::run () do { waitForEvent(); } while (true ); } void SurfaceFlinger::waitForEvent () mEventQueue->waitMessage(); } void MessageQueue::waitMessage () do { IPCThreadState::self()->flushCommands(); int32_t ret = mLooper->pollOnce(-1 ); } while (true ); }
可以看到 SurfaceFlinger 主线程通过死循环执行 MessageQueue.waitMessage 方法等待消息的到来,其内部调用的便是上面看过的 Looper.pollOnce 方法。
ET.onVSyncEvent 上面当 DispSync 同步模型产生 Vsync 信号后,会通知 DispSyncSource 源,进而回调监听者(EventThread)的 onVSyncEvent 方法。
1 2 3 4 5 6 7 8 void EventThread::onVSyncEvent (nsecs_t timestamp) std ::lock_guard<std ::mutex> lock (mMutex) mVSyncEvent[0 ].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC; mVSyncEvent[0 ].header.id = 0 ; mVSyncEvent[0 ].header.timestamp = timestamp; mVSyncEvent[0 ].vsync.count++; mCondition.notify_all(); }
onVSyncEvent 方法中执行 mCondition.notify_all 唤醒了 EventThread 线程,接着上面 EventThread 线程的逻辑开始看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void EventThread::threadMain () NO_THREAD_SAFETY_ANALYSIS std ::unique_lock<std ::mutex> lock (mMutex) while (mKeepRunning) { DisplayEventReceiver::Event event; Vector<sp<EventThread::Connection> > signalConnections; signalConnections = waitForEventLocked(&lock, &event); const size_t count = signalConnections.size(); for (size_t i = 0 ; i < count; i++) { const sp<Connection>& conn (signalConnections[i]) status_t err = conn->postEvent(event); } } } status_t EventThread::Connection::postEvent(const DisplayEventReceiver::Event& event) { ssize_t size = DisplayEventReceiver::sendEvents(&mChannel, &event, 1 ); return size < 0 ? status_t (size) : status_t (NO_ERROR); } ssize_t DisplayEventReceiver::sendEvents (gui::BitTube* dataChannel, Event const * events, size_t count) return gui::BitTube::sendObjects(dataChannel, events, count); }
这里通过 BitTube::sendObjects 发送数据,根据前面 addFd 方法的解析,当接收到数据时,会调用 MessageQueue::cb_eventReceiver 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int MessageQueue::cb_eventReceiver (int fd, int events, void * data) MessageQueue* queue = reinterpret_cast <MessageQueue*>(data); return queue ->eventReceiver(fd, events); } int MessageQueue::eventReceiver (int , int ) ssize_t n; DisplayEventReceiver::Event buffer[8 ]; while ((n = DisplayEventReceiver::getEvents(&mEventTube, buffer, 8 )) > 0 ) { for (int i = 0 ; i < n; i++) { if (buffer[i].header.type == DisplayEventReceiver::DISPLAY_EVENT_VSYNC) { mHandler->dispatchInvalidate(); break ; } } } return 1 ; } void MessageQueue::Handler::dispatchInvalidate() { if ((android_atomic_or(eventMaskInvalidate, &mEventMask) & eventMaskInvalidate) == 0 ) { mQueue.mLooper->sendMessage(this , Message(MessageQueue::INVALIDATE)); } } void MessageQueue::Handler::handleMessage(const Message& message) { switch (message.what) { case INVALIDATE: android_atomic_and(~eventMaskInvalidate, &mEventMask); mQueue.mFlinger->onMessageReceived(message.what); break ; case REFRESH: android_atomic_and(~eventMaskRefresh, &mEventMask); mQueue.mFlinger->onMessageReceived(message.what); break ; } }
于是进入 SF.onMessageReceived 方法,开始进行图形合成输出逻辑。
图像合成流程 SF.onMessageReceived 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void SurfaceFlinger::onMessageReceived (int32_t what) switch (what) { case MessageQueue::INVALIDATE: { bool frameMissed = !mHadClientComposition && mPreviousPresentFence != Fence::NO_FENCE && (mPreviousPresentFence->getSignalTime() == Fence::SIGNAL_TIME_PENDING); if (frameMissed) { mTimeStats.incrementMissedFrames(); if (mPropagateBackpressure) { signalLayerUpdate(); break ; } } bool refreshNeeded = handleMessageTransaction(); refreshNeeded |= handleMessageInvalidate(); refreshNeeded |= mRepaintEverything; if (refreshNeeded) { signalRefresh(); } break ; } case MessageQueue::REFRESH: { handleMessageRefresh(); break ; } } }
SF.signalLayerUpdate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void SurfaceFlinger::signalLayerUpdate () mEventQueue->invalidate(); } void MessageQueue::invalidate () mEvents->requestNextVsync(); } void EventThread::Connection::requestNextVsync() { mEventThread->requestNextVsync(this ); } void EventThread::requestNextVsync (const sp<EventThread::Connection>& connection) std ::lock_guard<std ::mutex> lock (mMutex) if (mResyncWithRateLimitCallback) { mResyncWithRateLimitCallback(); } if (connection->count < 0 ) { connection->count = 0 ; mCondition.notify_all(); } }
这里看一下 mResyncWithRateLimitCallback 参数,它是在 SF 初始化创建 EventThread 时传入的,mResyncWithRateLimitCallback() 调用的是 SF.resyncWithRateLimit 方法:
1 2 3 4 5 6 7 8 9 10 11 void SurfaceFlinger::resyncWithRateLimit () static constexpr nsecs_t kIgnoreDelay = ms2ns(500 ); static nsecs_t sLastResyncAttempted = 0 ; const nsecs_t now = systemTime(); if (now - sLastResyncAttempted > kIgnoreDelay) { resyncToHardwareVsync(false ); } sLastResyncAttempted = now; }
因此 signalLayerUpdate 方法的作用是请求接收下一次 Vsync 信号。
SF.handleMessageTransaction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bool SurfaceFlinger::handleMessageTransaction () uint32_t transactionFlags = peekTransactionFlags(); if (transactionFlags) { handleTransaction(transactionFlags); return true ; } return false ; } void SurfaceFlinger::handleTransaction (uint32_t transactionFlags) transactionFlags = getTransactionFlags(eTransactionMask); handleTransactionLocked(transactionFlags); }
SF.handleMessageInvalidate 1 2 3 4 5 6 bool SurfaceFlinger::handleMessageInvalidate () ATRACE_CALL(); return handlePageFlip(); }
SF.handleMessageRefresh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void SurfaceFlinger::handleMessageRefresh () nsecs_t refreshStartTime = systemTime(SYSTEM_TIME_MONOTONIC); preComposition(refreshStartTime); rebuildLayerStacks(); setUpHWComposer(); doComposition(); postComposition(refreshStartTime); mLayersWithQueuedFrames.clear(); }
代码过多,篇幅所限,具体的代码不贴出来了,需要的话可以去 SurfaceFlinger.cpp 的源码中查阅。
总结 在 SurfaceFlinger 的启动流程中:
首先会创建 SurfaceFlinger 对象,在构造器中创建了 DispSync 同步模型对象;
然后执行初始化 SurfaceFlinger 的逻辑:
注册监听,接收 HWC 的相关事件。
启动 APP 和 SF 的 EventThread 线程,用来管理基于 DispSync 创建的两个 DispSyncSource 延时源对象,分别是用于绘制(app–mEventThreadSource)和合成(SurfaceFlinger–mSfEventThreadSource)。启动了 EventThread 线程后,会一直阻塞在 waitForEventLocked 方法中(期间会根据需要设置监听器),直到接收到 Vsync 信号 且至少有一个连接正在等待 Vsync 信号 才会继续执行线程逻辑,即通知监听者;
通过 MessageQueue.setEventThread 方法创建了一个连接,并通过 Looper.addFd 方法监听 BitTube 数据。
创建 HWComposer 对象(通过 HAL 层的 HWComposer 硬件模块 或 软件模拟产生 Vsync 信号),现在的 Android 系统基本上都可以看成是通过硬件 HWComposer 产生 Vsync 信号,而不使用软件模拟,所以下面解析都只谈及硬件 HWComposer 的 Vsync 信号 ;
初始化非虚拟的显示屏;
启动开机动画服务;
最后执行 SurfaceFlinger.run 逻辑,该方法会在 SurfaceFlinger 主线程通过死循环执行 MessageQueue.waitMessage 方法等待消息的到来,其内部调用了 Looper.pollOnce 方法,该方法会从 Looper.addFd 方法监听的 BitTube 中读取数据,当有数据到来时执行对应的回调方法。
当硬件或软件模拟发出 Vsync 信号时:
回调 SF 相关方法,SF 调用 DispSync 同步模型的方法处理 Vsync 信号(统计和计算模型的偏移和周期),并根据返回值判断是否使能/关闭 HWC Vsync 信号的发出。
DispSync 根据计算的偏移和周期计算下次 Vsync 信号发生时间,并通知监听者 Vsync 信号到达的事件,传递给 DispSyncSource 延时源,延时源通过 EventThread 来管理 Vsync 信号的收发。
EventThread 调用连接 Connection 对象向 BitTube 发送数据,触发 addFd 函数中设置的回调方法,回调方法进而调用 SF.onMessageReceived 函数,然后进行图像的合成等工作。
另一方面,Choreographer 会通过上面创建的 APP 延时源 mEventThreadSource 对象及其对应的 EventThread 线程来监听同步模拟发出的 Vsync 信号,然后进行绘制(measure/layout/draw)操作。具体逻辑见 Android-Choreographer原理 。
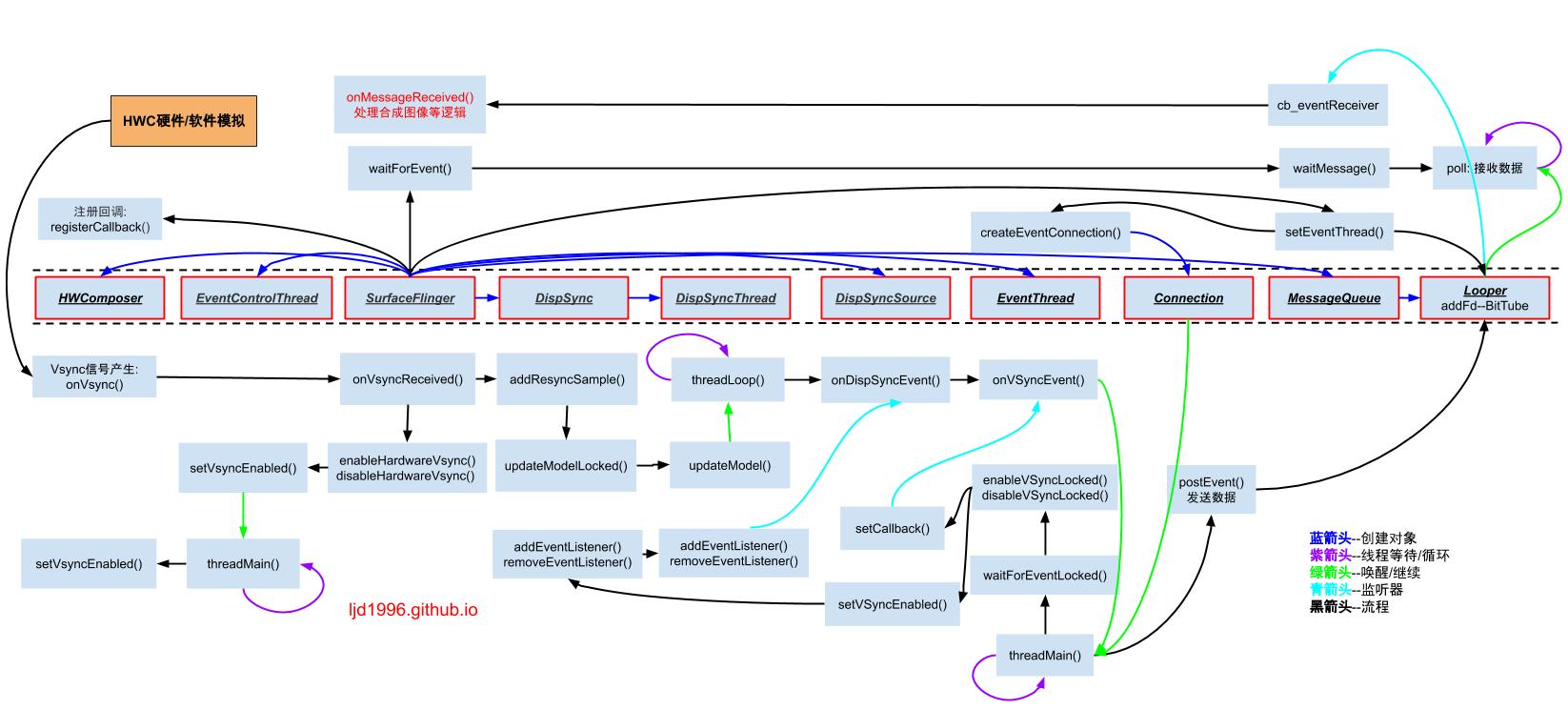
将 SurfaceFlinger 的工作流程总结如下图: